Les 4 Piliers de l'IA Agentique : Pourquoi vos agents plantent
Pourquoi un agent d'IA échoue en production et comment bâtir une architecture robuste autour de 4 piliers d'ingénierie.
Si vous lisez un énième post LinkedIn vous expliquant que « l’IA va révolutionner votre métier d’ici demain matin », vous avez probablement envie de fermer l’onglet. Et vous auriez raison.
Dans la réalité, quand on déploie des “agents d’IA” pour automatiser des tâches critiques, comme la veille réglementaire ou la préparation d’un audit de conformité, la déception est souvent rapide. L’agent invente un article de loi, boucle à l’infini sur une requête, ou s’effondre dès qu’une API externe ralentit.
Pourquoi ? Parce qu’un agent d’IA n’est pas magique. C’est un assemblage d’ingénierie.
Pour dépasser le stade du gadget et construire des systèmes autonomes fiables, il faut structurer son architecture autour de 4 piliers fondamentaux : le Prompt Engineering, le Context Engineering, le Harness Engineering et le Loop Engineering.
Pour comprendre comment ces briques s’assemblent sans se noyer dans le jargon des chercheurs, prenons une analogie universelle : la cuisine d’un grand restaurant étoilé.

1. Prompt Engineering : La Recette et les Consignes du Chef
Dans une cuisine, si vous dites à un apprenti : « Fais-moi une bonne entrée », vous prenez un risque immense. Le résultat dépendra entièrement de son humeur et de sa propre définition d’une “bonne entrée”.
En IA, c’est identique. Le Prompt Engineering n’est pas l’art de murmurer à l’oreille des modèles. C’est l’écriture d’une structure d’instructions stricte conçue pour canaliser des probabilités statistiques. Un LLM (Large Language Model) est un moteur de prédiction de mots. Plus ses instructions sont larges, plus la dispersion statistique est grande, et plus le risque d’hallucination (l’invention pure et simple) augmente.
Pour obtenir un comportement déterministe et fiable, une consigne robuste doit comporter quatre éléments :
- Le Rôle (Le périmètre d’expertise) : Définir qui est l’agent. « Tu es un auditeur QSE spécialisé dans la norme ISO 9001:2015 en PME industrielle. » Cela active les zones sémantiques pertinentes du modèle.
- La Matrice des Interdits (Les frontières opérationnelles) : C’est le point le plus important pour garantir la sécurité. Vous devez lister ce que l’agent ne doit jamais faire. « N’interprète jamais une exigence réglementaire sans citer le numéro d’article précis. N’invente aucun texte de loi si tu ne le trouves pas dans le contexte fourni. »
- L’Axe de la Tâche (L’action principale) : Isoler l’objectif immédiat pour éviter que le modèle ne dilue son attention sur des détails secondaires.
- Le Schéma de Sortie (Le format de dressage) : Comment le plat doit être présenté. En production, on interdit les réponses en texte libre. On exige un format structuré (un schéma JSON typé) validé par des outils comme Pydantic. Si le modèle ne respecte pas précisément le schéma de données attendu, l’assiette ne part pas en salle.
C’est la seule façon d’avoir un comportement déterministe avec une technologie probabiliste.
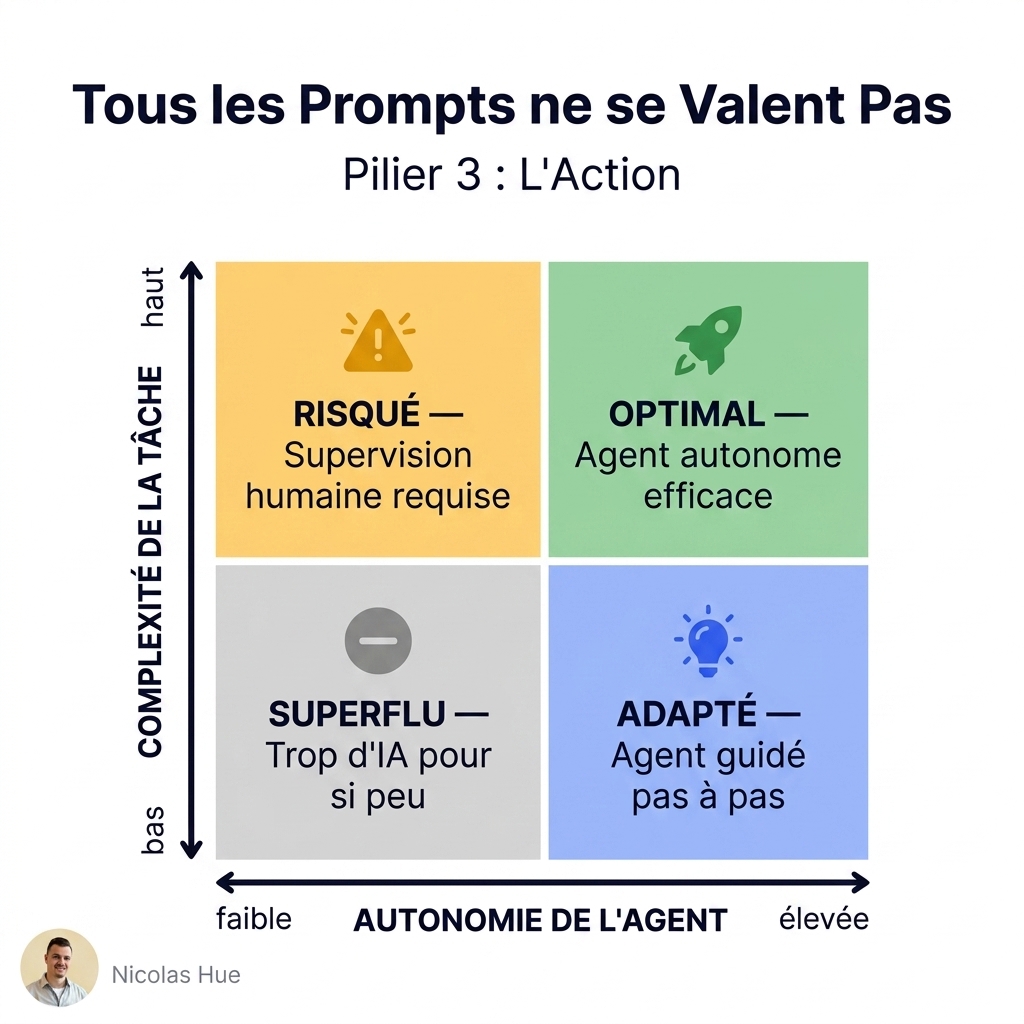
2. Context Engineering : Le Garde-Manger et la Mise en place
Imaginez un cuisinier qui, pour préparer un simple tartare de saumon, sortirait l’intégralité des ingrédients et des boîtes de conserve de sa réserve sur son plan de travail. La table serait encombrée, il perdrait un temps fou à chercher le sel, et risquerait de faire tomber un bocal.
Le Context Engineering résout ce problème. La mémoire de travail d’un LLM (la fenêtre de contexte) est limitée et coûteuse. Injecter des centaines de pages de normes ISO et de décrets dans chaque requête est une triple erreur :
- Financière : Vous payez chaque token (mot ou morceau de mot) envoyé et reçu.
- Technique : Les modèles souffrent du phénomène de Lost in the Middle (perdu au milieu). Plus le contexte est volumineux, plus le modèle a du mal à prêter attention aux informations situées au milieu du document. Il se focalise sur le début et la fin, et manque les détails critiques.
- Qualitative : Le bruit sémantique perturbe la pertinence de la réponse.
La solution consiste à mettre en place un filtre de pertinence (souvent via une architecture RAG - Retrieval-Augmented Generation). C’est la “mise en place” du cuisinier. Avant d’interroger le modèle, un système intermédiaire recherche dans votre base documentaire uniquement les 3 ou 4 clauses de la norme ISO concernées par la question. Seules ces données critiques sont placées sur le “plan de travail” du LLM.
3. Harness Engineering : Les Ustensiles et la Sécurité de la Cuisine
Un chef de cuisine a beau connaître la recette par cœur (Prompt) et avoir ses ingrédients alignés devant lui (Context), il ne peut rien faire si ses plaques de cuisson sont éteintes, ses couteaux émoussés, ou s’il n’a pas de four.
Le Harness Engineering (le harnais) désigne l’environnement technique externe fourni à l’agent pour lui permettre d’agir sur son environnement. Le modèle de langage seul est juste un “cerveau dans une boîte”. Pour qu’il devienne un agent, il lui faut des mains : des outils (APIs, scripts Python, accès en lecture/écriture à des bases de données).
Dans un système professionnel, le Harness est le garant de la sécurité opérationnelle et de la résilience :
- Le Sandboxing (La zone de découpe sécurisée) : L’agent doit exécuter ses outils (par exemple, un script d’analyse de données) dans un environnement isolé. S’il génère un script défaillant, celui-ci ne doit jamais corrompre vos serveurs ou vos fichiers de production.
- La Résilience Réseau (L’anti-panne) : Si l’agent doit interroger l’API de Légifrance pour sa veille réglementaire, le Harness doit gérer les latences et les pannes. Il implémente des mécanismes de rate limiting (pour ne pas saturer l’API) et de retry exponentiel avec backoff (si l’API échoue, l’agent attend 1 seconde, puis 2, puis 4, avant d’abandonner proprement).
- L’Observabilité (Le registre de cuisine) : Chaque appel d’outil, chaque temps d’attente et chaque coût en token doit être tracé. C’est ce qui permet de auditer le système et d’assurer que les décisions de l’agent sont vérifiables.
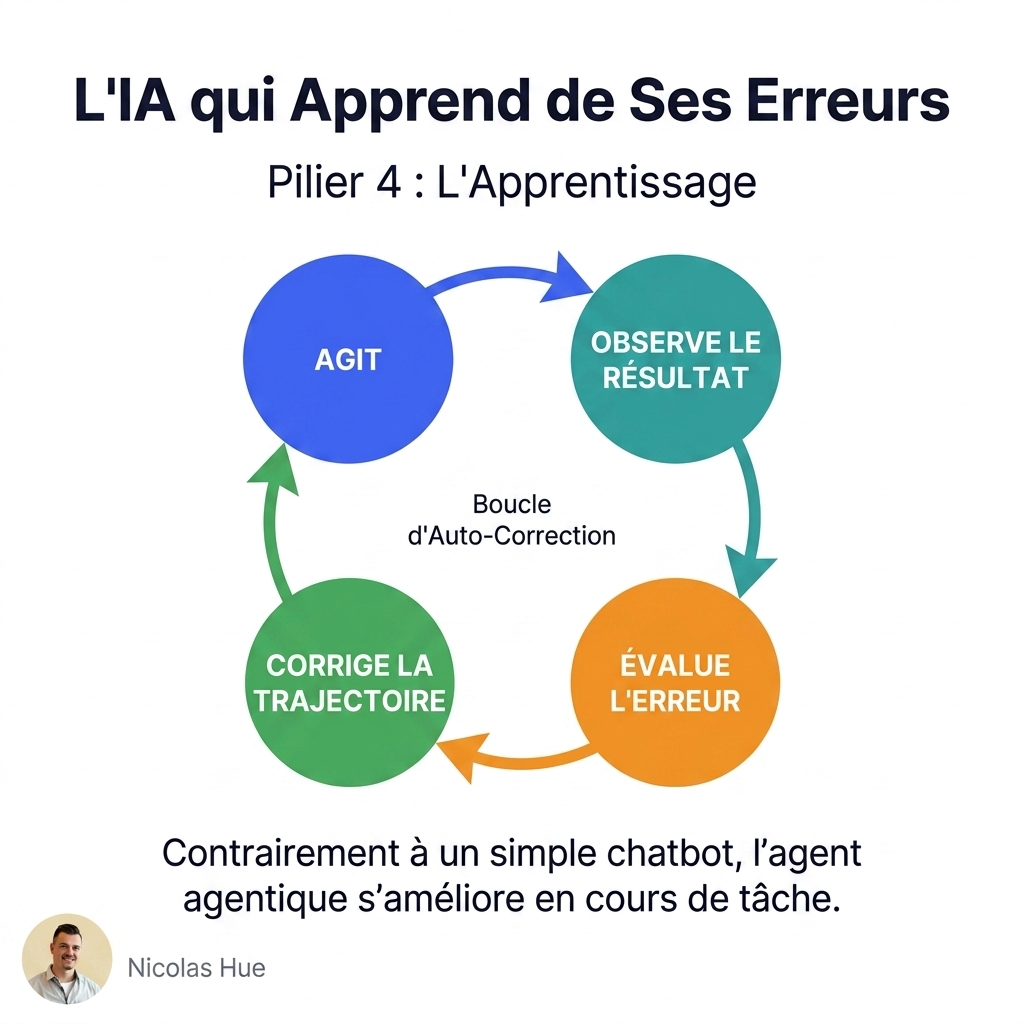
4. Loop Engineering : Le Goûtage et la Revue de Carte
Un cuisinier ne se contente pas de dresser l’assiette et de l’envoyer. Il goûte sa sauce en cours de cuisson. Si elle manque de sel, il ajuste, regoûte, et dresse seulement quand c’est conforme. En fin de service, le chef lit les retours des clients et ajuste sa carte pour la semaine suivante.
Le Loop Engineering est la gestion de ces boucles de rétroaction. On distingue deux niveaux essentiels :
A. La boucle d’exécution (Runtime Loop)
C’est le fait pour l’agent de s’auto-évaluer et de corriger ses erreurs avant de livrer son résultat. Par exemple, avec un workflow de type Reflection ou ReAct :
- L’agent génère un rapport de conformité.
- Un validateur de code ou un outil de vérification de schéma (le Harness) détecte qu’un champ obligatoire est vide.
- L’agent reçoit ce message d’erreur, analyse son propre travail, corrige le tir, et renvoie une version conforme.
B. La boucle d’apprentissage (Offline Loop & Reward Model)
C’est le retour d’expérience après livraison. Lorsque vous (l’utilisateur humain) corrigez un rapport généré par l’agent, cette correction doit être capturée. Elle sert à ajuster le modèle de récompense (Reward Model) ou à enrichir les exemples fournis à l’agent pour ses prochaines tâches.
Le risque majeur : L’effondrement de distribution (Distribution Collapse) Si vous ajustez continuellement le modèle uniquement sur les retours d’un petit groupe d’utilisateurs très bruyants ou très spécifiques, le système va sur-optimiser ses réponses pour eux. Il perdra alors sa capacité de généralisation et deviendra obsolète pour tous les autres utilisateurs ou pour les cas généraux. La boucle doit être équilibrée et représentative de vos véritables standards.
De l’exécutant manuel au commanditaire d’un système fiable
Pour le Responsable QSE qui passe ses journées à croiser des fichiers Excel, à surveiller des flux RSS réglementaires et à stresser à l’approche des audits, l’IA agentique n’a pas à être une boîte noire magique ou une menace légale.
En comprenant ces 4 piliers, on réalise qu’un système autonome n’est rien d’autre qu’une brigade de cuisine bien organisée. Le rôle du professionnel n’est plus de recopier des lignes manuellement (l’exécutant), mais de définir la recette (Prompt), d’organise le garde-manger (Context), de sécuriser la cuisine (Harness) et de goûter le plat final (Loop).
C’est cela, l’automatisation honnête.